Dynamic Reconfiguration with TornadoVM v1.0

13 March, 2024
Thanos Stratikopoulos, Juan Fumero, Christos Kotselidis (The University of Manchester)
Discover the innovative Dynamic Reconfiguration feature of TornadoVM, a groundbreaking technology crafted by the University of Manchester. Learn how this cutting-edge feature will be integrated into TANGO to significantly enhance energy efficiency, marking a leap forward in green computing.
TornadoVM is an open-source programming framework (originated in the University of Manchester) to unlock hardware acceleration for applications running atop the Java Virtual Machine (JVM). One of the features of TornadoVM is dynamic reconfiguration[1], that refers to the ability to migrate the execution from one device to another at runtime. This blog has the following objectives:
- Explain the basics of the dynamic reconfiguration feature in TornadoVM.
- Show how dynamic reconfiguration is triggered via the TornadoVM v1.0 API.
1. TornadoVM Dynamic Reconfiguration
TornadoVM enables multiple JDK distributions (e.g., OpenJDK, GraalVM, Amazon Corretto, Red Hat Mandrel, Eclipse Temurin, Azul Zulu) to offload the execution of Java methods on a plethora of heterogeneous hardware accelerator devices (e.g., multi-core CPUs, GPUs, FPGAs). When the dynamic reconfiguration feature is enabled, TornadoVM spawns a separate Java thread for each device in the system, as shown in the figure. Each thread is responsible for compiling the Java method to a parallel code block based on the characteristics of the targeted device, as well as executing the method on the device. Therefore, all threads are launched concurrently and the execution of the program can be migrated at runtime from the main thread (where the Java program is initially executed) to any other thread that corresponds to a hardware accelerator.
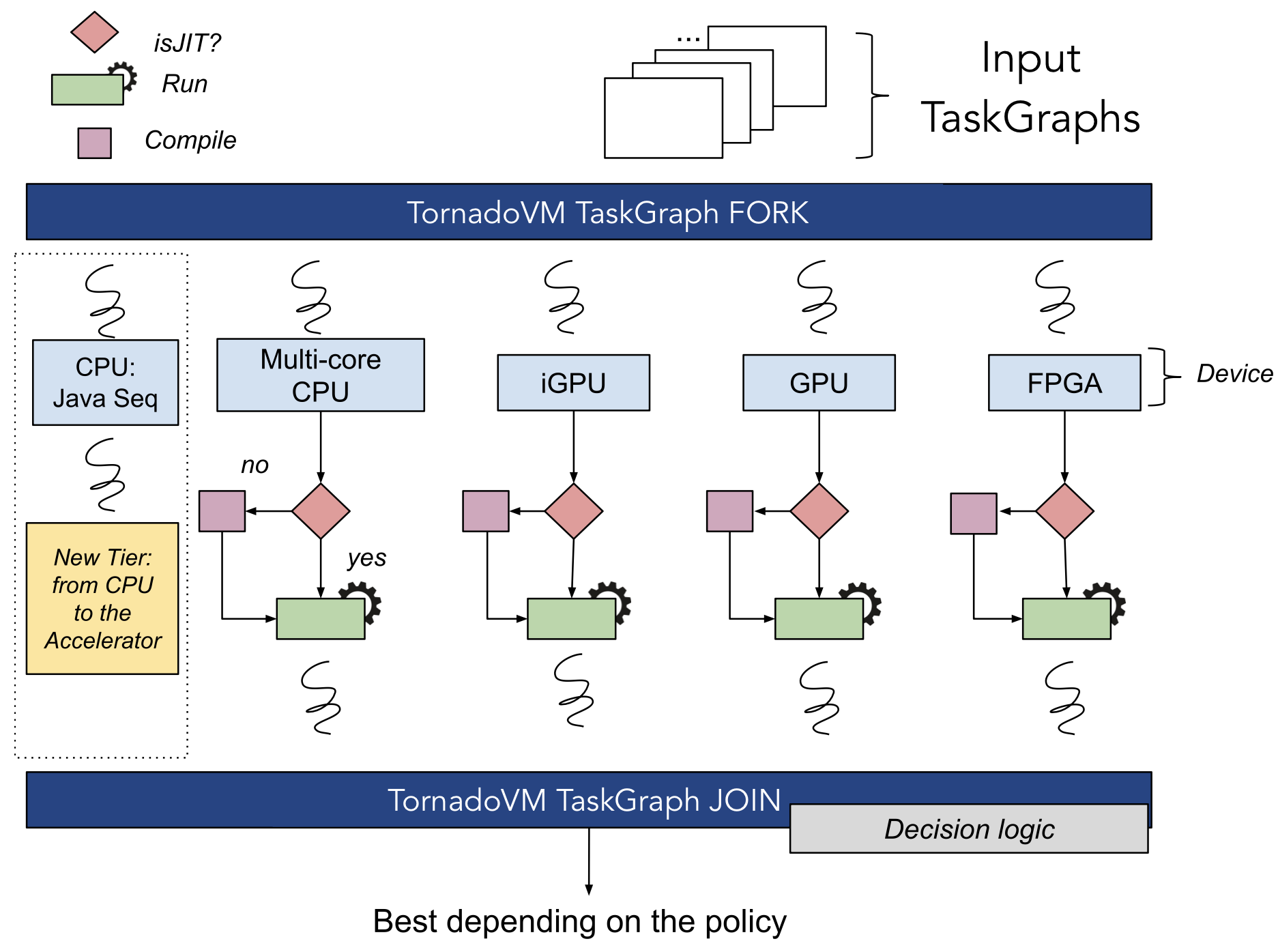
To take the decision upon which the migration of execution will be triggered, TornadoVM currently provides three policies:
- the END_2_END, which defines the best device by comparing the total execution time that includes the time spent on JIT compilation, data transfers, and computation.
- the LATENCY, which is similar to END_2_END but it does not wait for all threads to finish. The execution is completed when one of the spawned threads has finished.
- the PERFORMANCE, which defines the best device by considering only the data transfers and the computation time of a workload.
2. Enable Dynamic Reconfiguration in TornadoVM v1.0
In the current blog, we will show an example of how a Java programmer can enable and configure dynamic reconfiguration using the TornadoVM v1.0 API. We will use as an example of computation the saxpy computation which combines a scalar multiplication and a vector addition.
2.1. Use data types and express parallelism
The first step that a programmer needs to do is to carefully use the data types and express the parallelism within the method that is going to be executed on an accelerator.
public static void saxpy (float alpha, FloatArray x, FloatArray y) { for (@Parallel int i = 0; i < y.getSize(); i++) { y.set(i, alpha * x.get(i)); }}
As shown in the code snippet, the Java method of saxpy accepts as arguments a float value alpha, and two arrays of types FloatArray; which is a type exposed by TornadoVM to allocate data off-heap (more info here). Additionally, this method is annotated with the TornadoVM @Parallel annotation to define that the loop can be executed in parallel.
2.2. Use data types and express parallelism
Once those steps have been performed, programmers are ready to define a TaskGraph; a notion of which group of methods and data will be sent to the hardware accelerator.
int numElements = 16777216;FloatArray a = new FloatArray(numElements);FloatArray b = new FloatArray(numElements);a.init(10);
2.3. Define a TaskGraph
TaskGraph taskGraph = new TaskGraph("s0") //
.transferToDevice(DataTransferMode.FIRST_EXECUTION, a) // .task("t0", DynamicReconfiguration::saxpy, 2.0f, a, b) // .transferToHost(DataTransferMode.EVERY_EXECUTION, b);
In turn, a snapshot of the method is captured after finalizing the shape of the TaskGraph, resulting in an ImmutableTaskGraph object. To become familiar with these steps, you can read Sections 2 and 3 of the TornadoVM blog.
ImmutableTaskGraph immutableTaskGraph = taskGraph.snapshot();
2.4. Define a TornadoExecutionPlan
Once an ImmutableTaskGraph object is created, a Java programmer can create an execution plan to configure the execution of one of multiple immutable graphs. The execution plan can be configured by a programmer to define a policy (in this case PERFORMANCE is selected), and the dynamic reconfiguration mode[2], as follows:
TornadoExecutionPlan plan = new TornadoExecutionPlan(immutableTaskGraph).withDynamicReconfiguration(Policy.PERFORMANCE, DRMode.PARALLEL);
2.5. Execute with dynamic reconfiguration
When the configuration is complete, the execution of the plan can be triggered by invoking the execute method:
plan.execute();
You can run the whole example, assuming that you have more than one available devices:$git clone https://github.com/beehive-lab/TornadoVM.git && cd TornadoVM$./bin/tornadovm-installer --jdk jdk21 --backend opencl$tornado --devices$tornado -m $tornado.examples/uk.ac.manchester.tornado.examples.dynamic. DynamicReconfiguration
3. Scope within TANGO
In TANGO, the University of Manchester aims to extend TornadoVM with a new policy regarding energy efficiency. This will be the springboard for making decisions at runtime regarding the optimal deployment of an application at the granularity of a single compute node. More information regarding the dynamic reconfiguration and TornadoVM is available here.
[1] https://jjfumero.github.io/files/VEE2019_Fumero_Preprint.pdf
[2] The mode defines whether all threads will run concurrently (via DRMode.PARALLEL) or sequentially (via DRMode.SERIAL).